 DataWorks
DataWorks Hany Hossny
Hany HossnyData Science Process: From Business to Delivery
The Data Science Process
Data science projects start with business needs and go through data analysis, model development, deployment to production, quality assurance, and after-deployment support. The image below illustrates the key steps and actions included in each step during the life cycle.

Data Science Process from Business to Delivery
The Deliverables

Data Science Deliverables
Along the development life cycle, each project can deliver multiple deliverables according to the business need, as listed below.
- Descriptive reports, including statistical analysis, correlation analysis reports, and descriptive dashboards.
- Predictive model, including the model APIs, features importances, sensitivity analysis reports, and what-if dashboards.
- Prescriptive models include optimisation processes and prescribing the best values for the predictor variables that maximise the value of the target variable.
Development Process
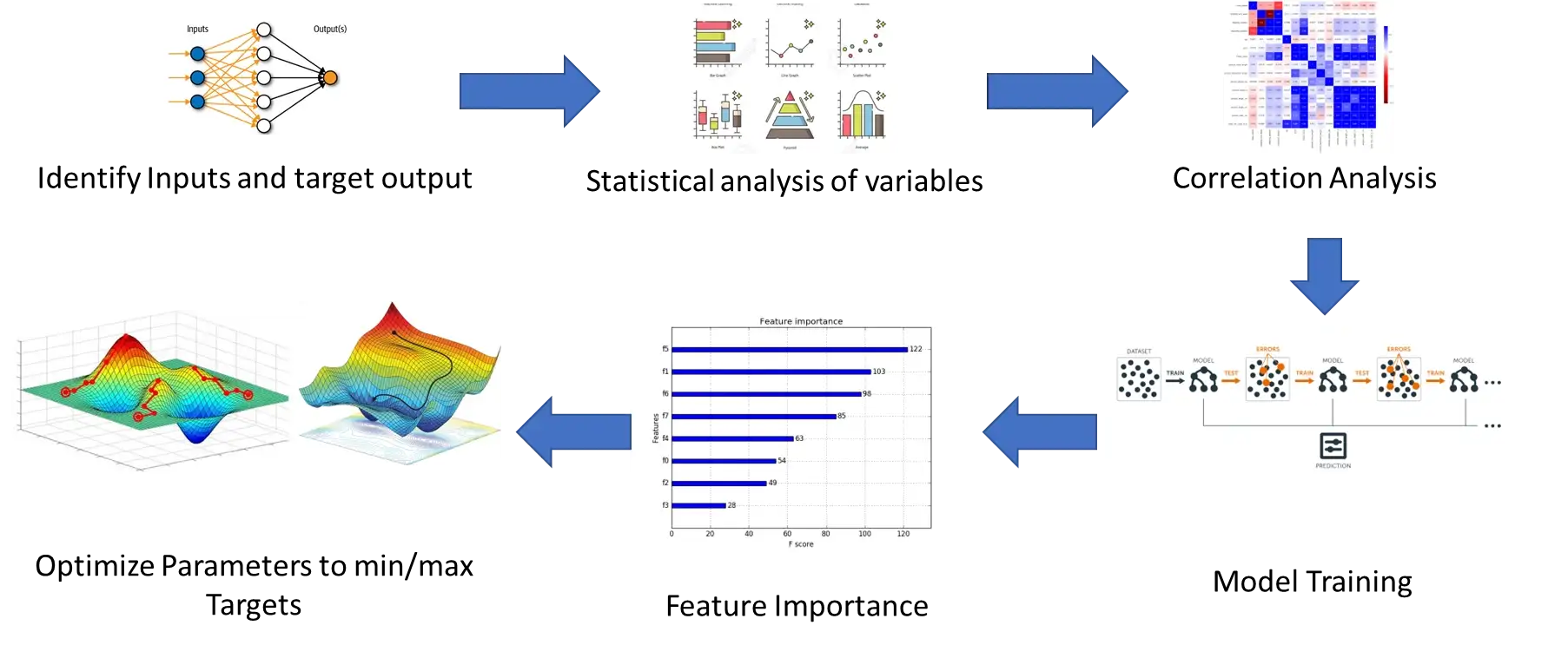
Data Science Development Process
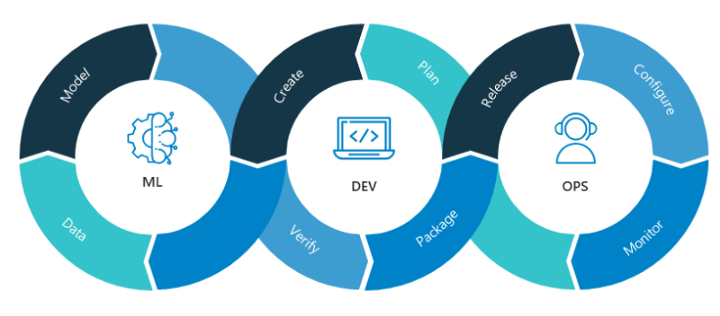
Every machine learning model has the components below developed as part of the development journey, which is the technical part of the bigger life cycle of the data science life cycle.
- Data collection pipeline: this is where we search for valid data points that can affect the target variables. This usually requires digging into the database, or data warehouse, building some SQL queries that populate the data and aggregating them into a denormalised table that maps the descriptors to the target variable.
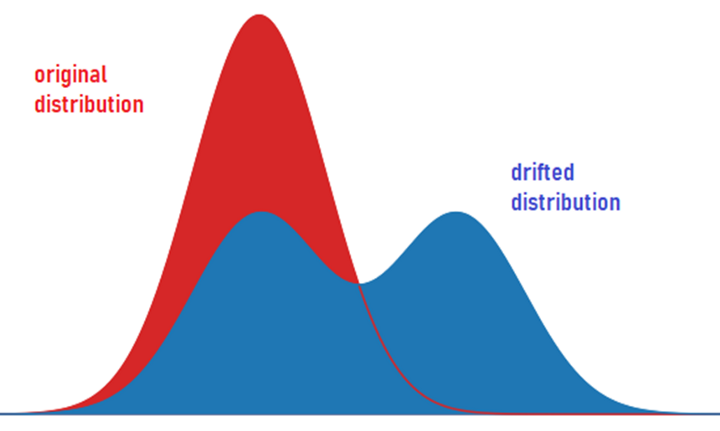
- Exploratory data analysis: this is to understand the basic statistical properties of the data, such as the statistical distribution, histogram analysis, correlation with the target variable, and intercorrelation with other variables
- Feature engineering: This is to prepare the data to be interpreted by the machine learning algorithms regardless of the basic human understanding. This can be implemented using feature differentiation, feature generation and feature reduction. The premise here is that sometimes data have latent relation that is not visible to the analyst’s eye or even to the known statistical algorithms. This is why algorithms such as PCA, ICA, and Autoencoders can help transform the data to higher dimensions that reveal the data nature to the algorithms.
- Model development: This is basically to train the algorithm on the prepared data to learn to find the patterns inside and generalise them to maximise the accuracy of the predictions and minimise the errors. Obviously, a big part of this is optimising the model to find the best set of parameters to achieve the highest value. Another extension to the ML model is to develop an optimisation model that prescribes the best set of input features that maximises the target variables.
- Deployment to production: This step needs to be very responsive, as with each change at any of the previous 4 steps should be reflected in the deployment process, which takes a long time and hard work from the dev-ops teams
- Model consumption: This is where the model will be used by the front-end that provides the predictive modelling as a service to the end-user. The model can be deployed as either a live API or as a batch export. These deployments can be consumed via a dashboard, a digital app (web/mobile), a messaging app or a third-party tool that consumes the batch exports.
Data Science Consumption

data science projects consumption methods
Data science projects aim to support the end-user by providing appealing products/services or the business stakeholder by providing insights or advice to maximise the business’s success. The models are usually consumed through digital apps, communication channels, descriptive dashboards, or exported data.
- Digital apps include mobile and web applications that send the data to the model API at runtime and get the predictions and render the output to the digital channel directly to the end user. The end user will receive the predicted variables (such as recommended item, expected delivery time, etc.) to decide what is his next action through this web channel.
- Static reports render the insights coming from the EDA and model feature importance as actionable insights for decision-makers
- Interactive dashboards deliver a what-if analysis interface to the model APIs, where the decision maker puts a hypothetical scenario for the data used as predictors and gets the predicted target as an output.
- Chatting apps can learn the user preferences, the scenario nature and the historical performances and respond to the end user instantly.
- Communication channels (such as marketing emails or social media ads) learn the user preferences and historical performances to recommend the most appealing products or services to the end-user.
- Integration services use the exported prediction as performance indicators, as input to another model, or as input to a third-party tool.
The Operations
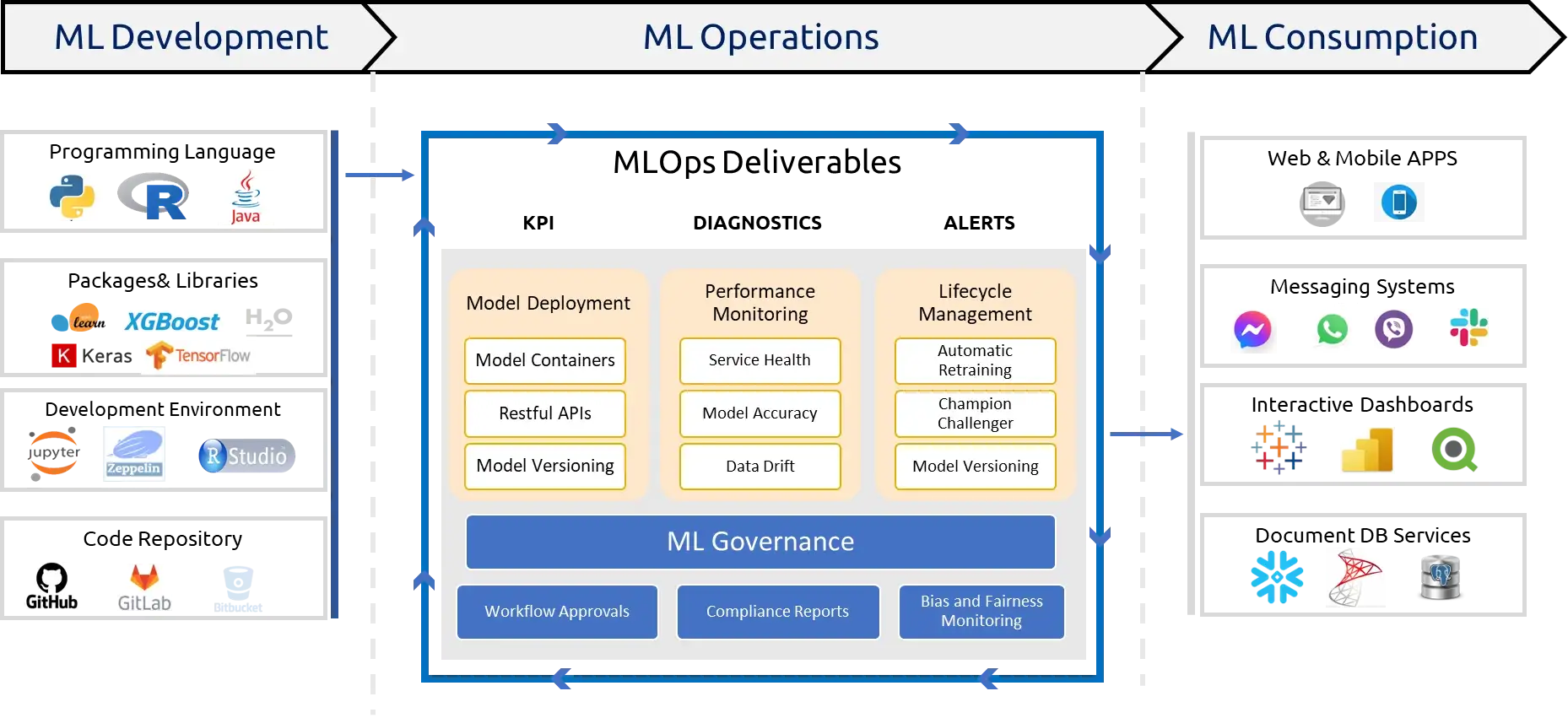
MLOPS deployment, production and runtime
Finally, once the model is delivered and deployed, we should consider how to operationalise the model. This will include governance, support, monitoring, service health, runtime issues, continuous evaluation, continuous training, and continuous deployment.
Conclusion
The data science life cycle and process are long and comprehensive. It requires understanding lots of steps and actions in the development, operations and science. Once the process is established at any firm, any data science project can be developed in around 3–4 weeks from business to delivery.
The key action is to secure the investment to build the DS process, team and platform. Once done, the Business will get returns 10 times the investments put into the DS team.
Connect on LinkedIn: https://www.linkedin.com/in/hanyhossny/
Read other articles: https://hany-hossny.medium.com/
Follow on Twitter: https://twitter.com/_HanyHossny
Hany is an AI/ML enthusiast, academic researcher, and lead scientist @ Catch.com.au Australia. I like to make sense of data and help businesses to be data-driven