 DataWorks
DataWorks Hany Hossny
Hany HossnyData Science Delivery Practices
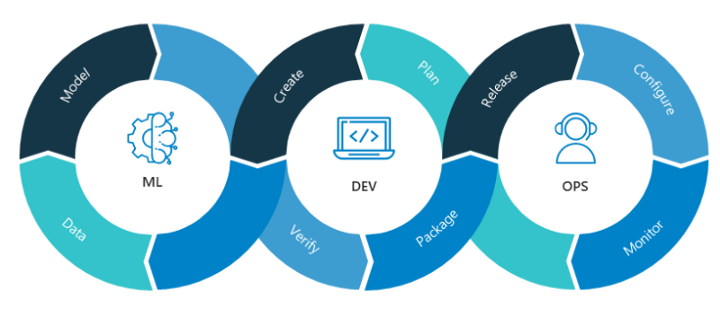
Machine Learning vs Traditional Modelling/Programming
Data science is the process of building models that analyze historical data and learn the pattern bridging the input and the output in a way that can be repeated using future data coming as input and predicting the target variables and delivering them as output. The machine learning models are typical functions that follow standard APIs and services practices, except they have special MLOps (ML-DevOps) requirements due to their experimental nature in addition to ModelOps (ML-Runtime-Ops) due to the continuously changing nature of data.

Machine Learning Delivery Methods:
Data science and ML models can be delivered in multiple ways, depending on the problem’s nature and the ecosystem infrastructure.
- Restful API that can be called as needed by the consumer who passes the input parameters and receives the output value
- Batch API that receives a data set of multiple records, applies the model using all the passed data and returns an array of predicted values
- Synchronous calls can be implemented by calling the restful API in a timely manner from the API-consumer side in a chron-job.
- Service mesh uses an API hosting layer above the data mesh, but this requires the data to be decentralised and the architecture to be generalised and the governance to be implemented, and the API layer to be configured (This is the most mature and advanced solution, but it is not feasible). This can be described as a more advanced version of the restful API, where different teams can own and host the APIs using platform tools.
- ETL pipeline is a highly unrecommended solution due to the high coupling of model/consumer code and the likelihood that ETL gets broken or falls out of synchronisation with the API-consumer, which will require frequent human interference.
- Model packaging into a software library that is integrated with the consumer application (WebAPP, MobileAPP, embedded device). This makes us lose all control over the model unless the monitoring/tracking is implemented on the App side. This is only recommended for the use of offline embedded devices such as drones or free-roaming robots.
API Delivery Practices:
As the model development process delivers a service by taking input values and delivering outputs accordingly, it should follow the best practices for conventional API deployment as listed below. The AI-API deployment process is very similar to any other API, but what happens behind the API interface can be very different due to the dynamic nature of data science projects.
- Gateway: The API should be deployed on an API gateway that provides a unified interface for all APIs using function signatures
- Web-service: The API should be hosted as a restful web service that receives the known input and delivers the known output (as greed in the API contract), The functions should be accessible via web request (HTTP requests) using the post method
- JSON: The parameters should be passed in and out using either JSON to simplify data handling and delivery
- Policy Manager: To ensure compliance with accessibility rules such as Identity management, access limitations, delivery policies, integration policies and synchronization agreement
- Catalogue: Every API should be registered into an API catalogue describing its action, input, output, response time, error codes, and versions. Creating an API catalogue is important as bookkeeping, hub for your API management solution.
- Client Registry: This should contain the listing of B2B use cases, which applications can access which APIs, and a developer listing to ensure they have needed access and functionality. Some API management solutions include the registry as part of the catalogue.
- Developer Portal: This is the main tool for the proliferation of the API. This is where developers can build and test their app’s integration with your API, communicate among themselves, access useful documentation, view and/or acquire sample code and obtain security access keys.
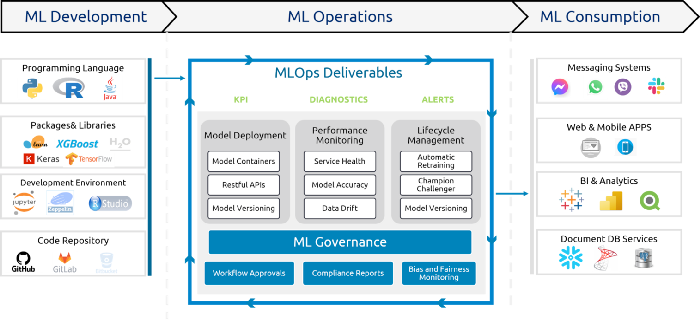
ML-Dev-Ops Practices
Successful ML deployments generally take advantage of a few key MLOps principles, which are built on the following pillars:
- Tracking — ML models are software artifacts that need to be deployed. Tracking provenance is critical for deploying any good software and is typically handled through version control systems. But, building ML models depends on complex details such as data, model architectures, hyperparameters, and external software. Keeping track of these details is vital, but can be simplified greatly with the right tools, patterns, and practices.
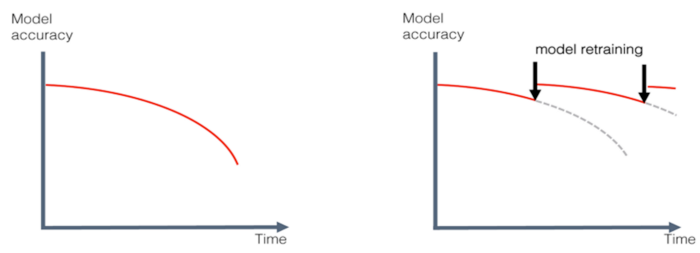
- Automation & DevOps — Automation is key to modern DevOps, but it’s more difficult for ML models. In a traditional software application, continuous integration and continuous delivery (CI/CD) pipeline would pick up some versioned source code for deployment. For an ML application, the pipeline should not only automate training models but also automate model retraining along with archival of training data and artifacts.
- Monitoring/Observability — Monitoring software requires good logging and alerting, but there are special considerations to be made for ML applications. All predictions generated by ML models should be logged in such a way that enables traceability back to the model training job. ML applications should also be monitored for invalid predictions or data drift, which may require models to be retrained.
- Reliability — ML models (especially deep learning models) can be harder to test and more computationally expensive than traditional software. It is important to make sure your ML applications function as expected and are resilient to failures. Getting reliability right for ML requires some special considerations around security and testing.
ML-Runtime-Ops Practices:
Once the model is deployed, it should be continuously monitored to ensure the sustainable quality of the service delivery. This will require following the standard runtime API management practices as listed below.
- Ensure API is available and minimize downtime.
- Ensure the API performs reliably under stress or overload.
- Minimize the response time for the API.
- Ensure security compliance.
- Ensure every input and output is logged, which will be used later for evaluation and performance tracking
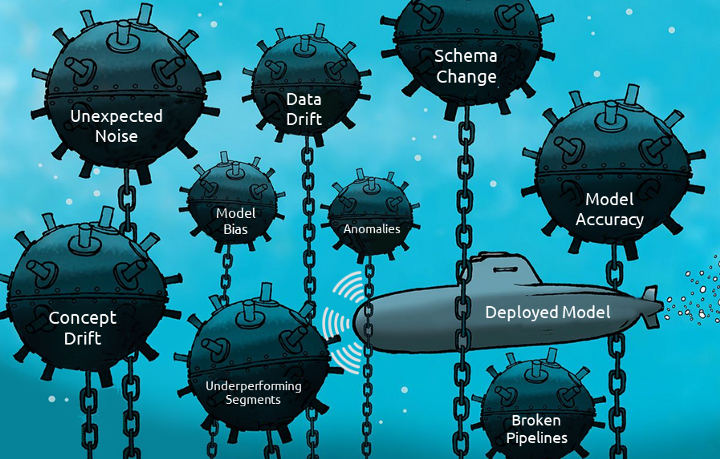
- Ensure the continuous evaluation of the model against data drift and concept drift
- Ensure the continuous tracking for the model against anomalies and discriminative bias
- Ensure the availability of a backup model as a champion challenger in case the runtime model failed
The API Advantage
Hosting data science models as API is important to enable MLOPs including CI/CD, virtualization, governance, traceability and accountability. In addition, using APIs enable ML-Runtime-Ops services including continuous training, performance tracking, champion challenger,
- Enable tracking latency measured in milliseconds. Are users guaranteed a seamless experience?
- Enable scalability measured in Queries Per Second (QPS). How much traffic can your service handle at the expected latency?
- Enable service update: How much downtime (service unavailability) is introduced during the update of your service’s underlying models?
- The contractual agreement between the ML squad and the business, where they pass a set of parameters with predefined types and we handover to them the results according to the agreement within a specific time frame and specific accuracy/confidence
- APIs are easier to monitor, maintain, and upgrade
- APIs allow the ML team to upgrade the backend models or change them completely without affecting the business
- APIs allow the ML team to monitor the model performance in the runtime and act accordingly if we found any runtime issues such as anomalies, data drift, concept drift, underrepresented segments, etc.
- APIs allow us to use the champion challenger in case of model failure
- APIs will enable us to reuse the same model for multiple use cases without affecting the business consumer
- APIs guarantee that the model and the business are loosely coupled, where any change in the business will not affect our models or our data and any change in our models or data will not affect the business performance
- APIs enable logging the input data and the output results, which allow us to track the performance of the model in the runtime
- APIs give us a clean and well-defined interface for analytics, which integrates easily with any application: a simple cURL command is all you need!
- APIs provide stability, where the algorithm or input data can change, but the API endpoint will remain the same.
- APIs check data and requests at the door. Because the request that the algorithm expects is so well defined, anything not corresponding to the specification will result in an error.
- APIs separate the iterative world of data science from the world of IT and software. Algorithms need frequent updates, while the software application from where they run needs to be stable, reliable and robust. This separation also means that the Data Scientists can focus on building models and don’t have to worry about the infrastructure.
- APIs open up data science models to the whole organization, or even customers or third parties. All in a secure and scalable way.
- APIs allow the model to be used by multiple applications at the same time, from any language or framework. No additional software or settings are required, so once the deployment is running, it can be queried immediately.
- In addition, as it’s a single API endpoint, there’s no need to configure a load-balancer or bypass a firewall. This is what some major cloud providers require, adding complexity to the infrastructure.
- Security is handled by only allowing requests to the model if they are signed with a token that holds the right permissions. This way it’s easy to only allow requests from inside your team, or open up the model to the rest of the world.
NON-API deployment
Without API, we cannot enable governance, traceability, accountability, continuous deployment, continuous training, contractual agreement, scalability, runtime performance tracking, champion challenger, security, logging, or service sustainability. This is because all these services use automation scripts, assuming all the models will follow the same ML-Dev-Ops pipeline where the model will be deployed as an API on the Catch API gateway server.

References
https://www.copado.com/devops-hub/blog/api-management-best-practices
http://techtarget.com/searchapparchitecture/tip/16-REST-API-design-best-practices-and-guidelines
https://www.phdata.io/blog/the-ultimate-mlops-guide-how-to-deploy-ml-models-to-production/
https://ubiops.com/the-benefits-of-machine-learning-apis/
https://hany-hossny.medium.com/introduction-to-mlops-1-29c9c025715f
https://hany-hossny.medium.com/mlops-vs-devops-how-different-are-they-mlops-2-8bcafeff1230
https://www.youtube.com/watch?v=1Kk7NE1RMVQ
3 ways to deploy machine learning
Hany is an AI/ML enthusiast, academic researcher, and lead scientist @ Catch.com.au Australia. I like to make sense of data and help businesses to be data-driven