 DataWorks
DataWorks Hany Hossny
Hany HossnyMachine Learning Runtime Challenges (Model-Ops)
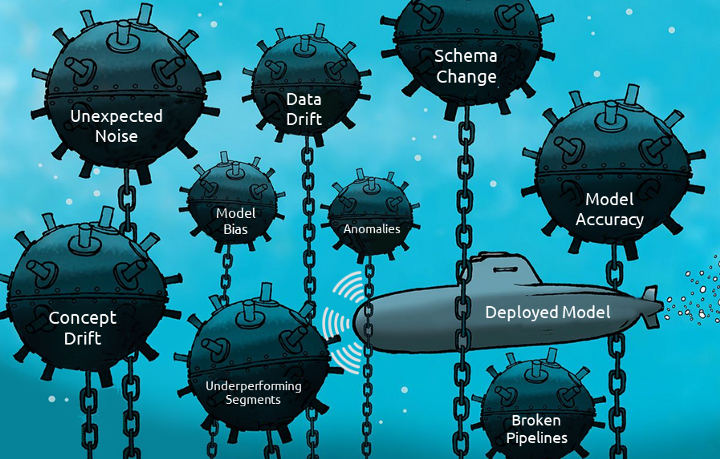
Once the ML model is deployed to production, many issues occur in runtime reducing the predictive accuracy and shortening the lifetime. Without monitoring, the model can easily hit any of the runtime bombs and fail due to data drift, concept drift, anomalies, etc.

Model-Ops performs continuous monitoring for the deployed model to preemptively detect any issues and fix them before they cause any troubles
Data Drift
Data drift happens when the input data stream follows a pattern different from the original pattern in the historical data that was used to train the model. It is also called feature drift, population, or covariate shift. Usually, data drift happens with temporal data, non-stationary data, heteroskedastic data and graph-based data. It means that the features (independent variables) used to build the model have changed, which means that the model or the equations that predict the target variable will have input other than the expected, which will lead to a prediction other than what it was supposed to be.
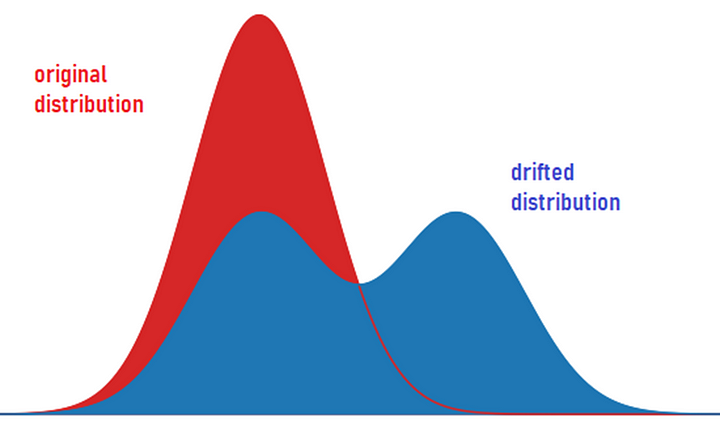
When a normally distributed data drifts to be bi-modal distributed, the current model is will not work as accurate as it should be
Concept Drift
Concept drift is the deviation of the target variable from its old pattern, it happens when the statistical features of the target variable change in the runtime. Considering that the trained model is a function mapping the input variables (or features), any change in the statistical or mathematical properties of the input or the output will lead to inaccuracies in the predicted values. The drift can be sudden, gradual, incremental, recurring or accidental.
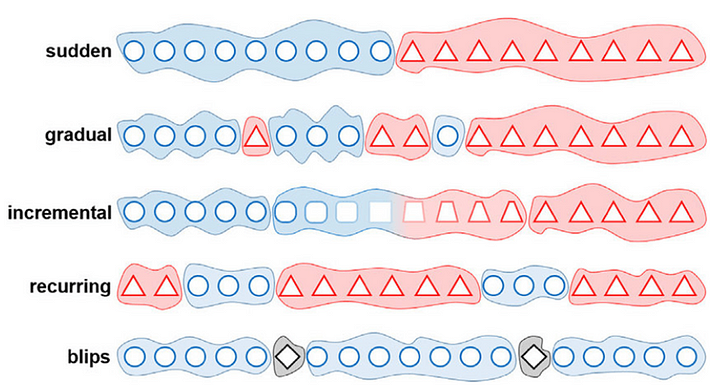
Variations of Target Drift
Underperforming Segments
Sometimes the model performance is good, except for a few instances of the input/output which are predicted significantly worse. If these instances fall in the same segment, this implies that we have partial drift for a subset of the data, especially if this segment was predicted accurately in the development and evaluation stage. Partial drifts are usually invisible as we evaluate the model performance as a whole, and the risk here is that we may lose a whole segment of our clients for no reason.
Discriminative Bias
This happens when a specific segment of the data has a specific prediction or recommendation based on a discriminatory feature. This might happen because the model learned the bias from historical biased data or because the segments discriminated against are underperforming. Both cases should be caught, addressed and fixed for performance, ethics and governance reasons.
Anomalies
Anomalies or outliers are rare observations in a way that is unlikely to occur again. Most scientists and ML experts opt to remove the anomalies from the data before building the model, which makes the model intolerant to future anomalies of the same nature. The problem here happens when the anomalies present phenomena of the data that might occur frequently. In such a case, the frequently occurring anomalies will cause the model to fail. The frequently occurring anomalies might have a unified nature or distribution to be detected in the runtime then they can be eliminated or included in the model accordingly.
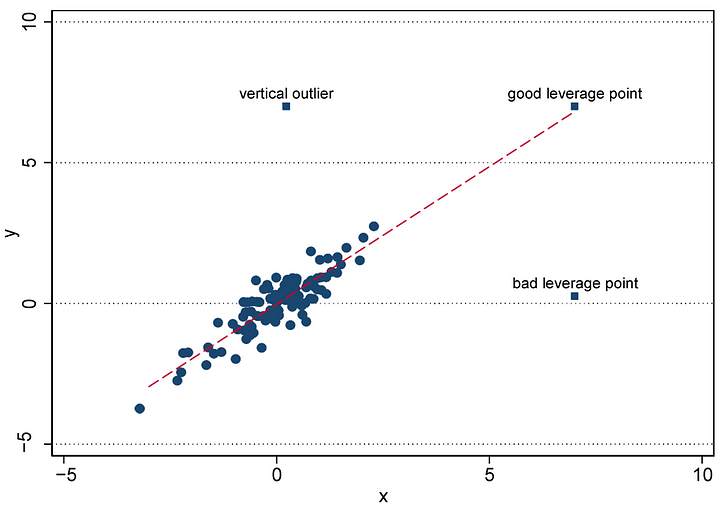
Outliers are not always bad, sometimes they are leverage that can help build a better model. blind elimination according to the distribution can cause losing informative observations
How to Enable ModelOps
Model Ops requires continuous monitoring, evaluation, training, tuning and deployment. Enabling this level of continuity and automation is the only way to guarantee that the model will be working in its best shape as long as possible.
- Continuous monitoring requires the developers to include logging in their model pipeline and will require the platform to log the input and output continuously.
- Continuous evaluation requires identifying the statistical descriptors of the historical input data and the historical target variable and calculating the same statistical descriptors using the same methods for the new data. Ideally, the new descriptors will be very similar to the old ones, but if there is any deviation, this might be a symptom of one of the issues mentioned above.
- Continuous training requires the ML-DevOps platform to enable automated training and tuning of the model using the recently added data. it will also require the developers to deliver the predictive model as well as the training pipeline that will be used to generate the new models
- Continuous deployment requires the ML-DevOps platform to support automatic deployment for the new models as well as the runtime retrained models.
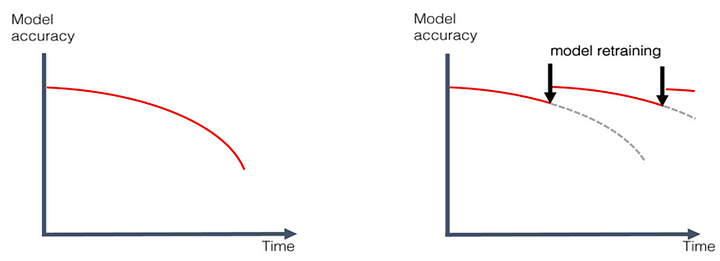
The perfect Model-Ops will enable the model to be retrained and deployed automatically once there is any runtime issue that affects the performance
References
- https://www.researchgate.net/publication/265097085_Do_theme_parks_deserve_their_success
- https://www.bmc.com/blogs/machine-learning-anomaly-detection/
- https://www.kdnuggets.com/2021/09/mlops-modelops-difference.html
- https://en.wikipedia.org/wiki/ModelOps
- https://www.modelop.com/modelops-and-mlops/
- https://evidentlyai.com/blog/machine-learning-monitoring-data-and-concept-drift
- https://evidentlyai.com/blog#!/tfeeds/393523502011/c/machine%20learning%20monitoring%20series
- https://evidentlyai.com/machine-learning-monitoring-how-to-track-data-quality-and-integrity
- https://medium.com/data-from-the-trenches/a-primer-on-data-drift-18789ef252a6
- https://www.explorium.ai/blog/understanding-and-handling-data-and-concept-drift/
- https://towardsdatascience.com/data-drift-part-1-types-of-data-drift-16b3eb175006
Hany is an AI/ML enthusiast, academic researcher, and lead scientist @ Catch.com.au Australia. I like to make sense of data and help businesses to be data-driven